Output example
Analysis charts
For each experiment, the Python script analisi_suffix.py generates
a six-panel chart from the CSV output. Below is a real example comparing two windows
at prefix 10¹⁶ with W = 510,502.
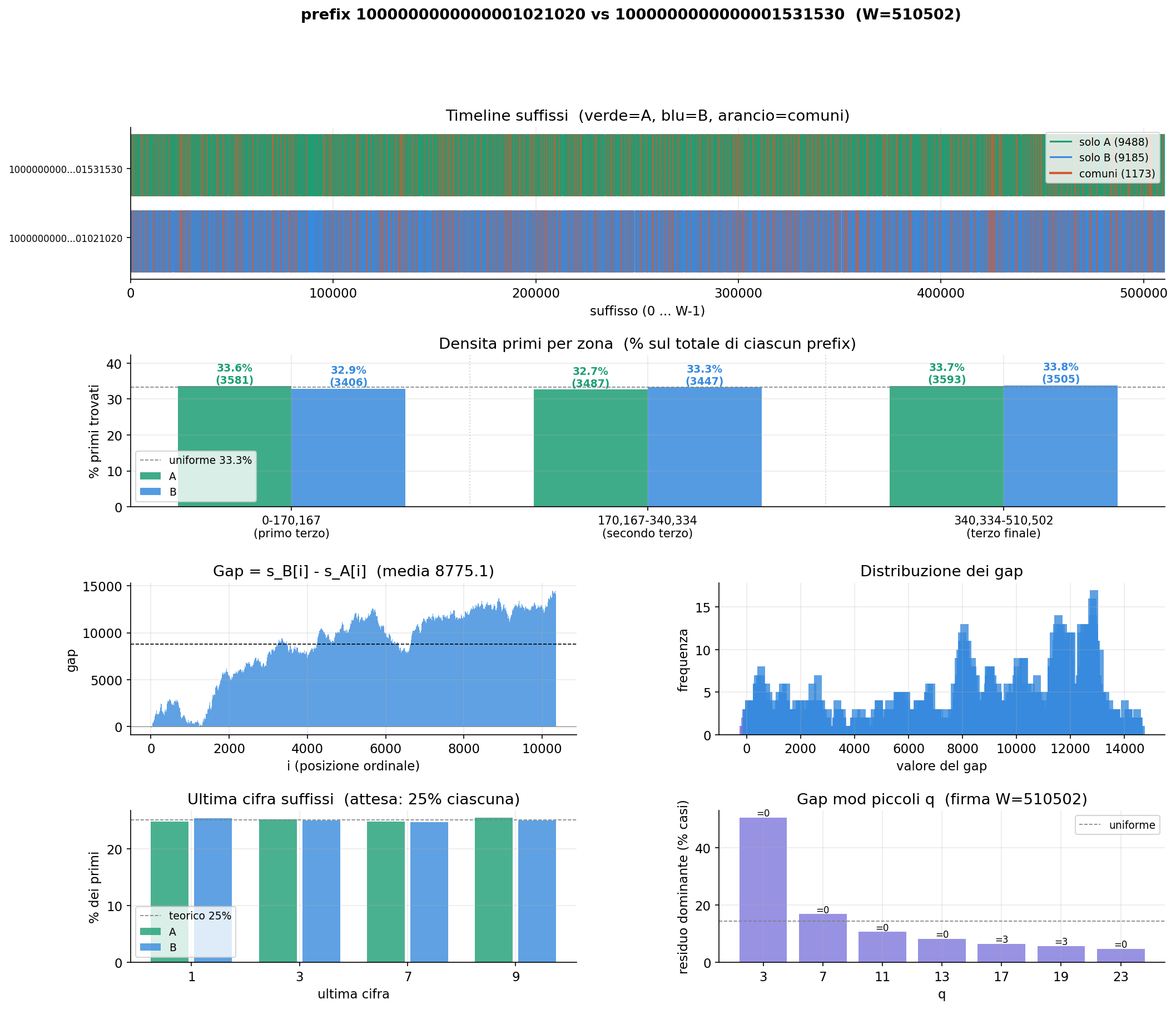
prefix 10000000000000001021020 vs 10000000000000001531530 — W = 510,502 ·
Solo A: 9,488 primes · Solo B: 9,185 primes · Common suffixes: 1,173
Each chart contains six panels:
Panel 1
Suffix timeline
Spatial distribution of primes in both windows, with common suffixes highlighted.
Panel 2
Density by thirds
How many primes fall in the first, second, and third third of each window.
Panel 3
Gap per position
s_B[i] − s_A[i]: the "race" between the two windows, moment by moment.
Panel 4
Gap distribution
Statistical snapshot of the entire race between the two windows.
Panel 5
Last digit
Verification of Dirichlet's theorem — expected 25% each for digits 1, 3, 7, 9.
Panel 6
Gap mod q
The modular signature of W — an invariant that depends only on window width, not on scale.